我们在 2.3 看到了对于单个离散的协变量 的分层与后分层. 但是如果协变量是多维的/连续的呢? 在这里我们介绍重随机化和回归调整.
|
设计 |
分析 |
| 离散的协变量 |
分层 |
后分层 |
| 一般的协变量 |
重随机化 |
回归调整 |
1 重随机化
1.1 实验设计
依然假设 个实验单元, 这里 个实验组 个对照组. 记 为指示实验组分配的向量. 有协变量 , 将他们合并成 协变量矩阵 . 假设 .
CRE 中 有均值 , 但实际分组中通常都不为 . 我们可以证明 这里 .
我们把 Neyman定理 从数值结果拓展为向量结果. 考虑向量结果的平均因果效应
估计量 则 是 的无偏估计.
我们可以用 Mahalanobis 距离
来定义实验、对照组的相异程度. 这个式子只在 可逆的时候有意义, 也即 的列线性无关. 我们要在实验前去掉线性相关的列.
如果我们对 做线性变换 , 这里 可逆, 则 保持不变.
当 很大, CRE 下 基本上就是 . 因此 在 很大时几乎有均值 和方差 . 当我们进行随机化, 我们评估 的值, 当它很大时我们舍弃它, 这样就实现了重随机化.
从 CRE 中采样 , 只在 的时候接受它, 这里 是我们事先确认的常量.
当 很大时, 几乎就是 CRE; 当 很小时, 没有什么随机化的空间基本上没用. 我们一般选一个小的但是不是特别小的 , 例如 , 或者一些 的较大的分位数.
1.2 统计推断
如果我们不给出很强的零假设, 如何得到有限样本的相关性质? 我们定义下面的假设条件:
当 时,
- , 有正的极限.
- 的协方差有有限的极限
- , , .
记 这里 服从一个 维标准正态分布; 记 服从标准正态分布, .
在 的 ReM 和上述假设下, 这里 是我们在 Neyman 定理里证明过的样本方差, 是相关系数的平方.
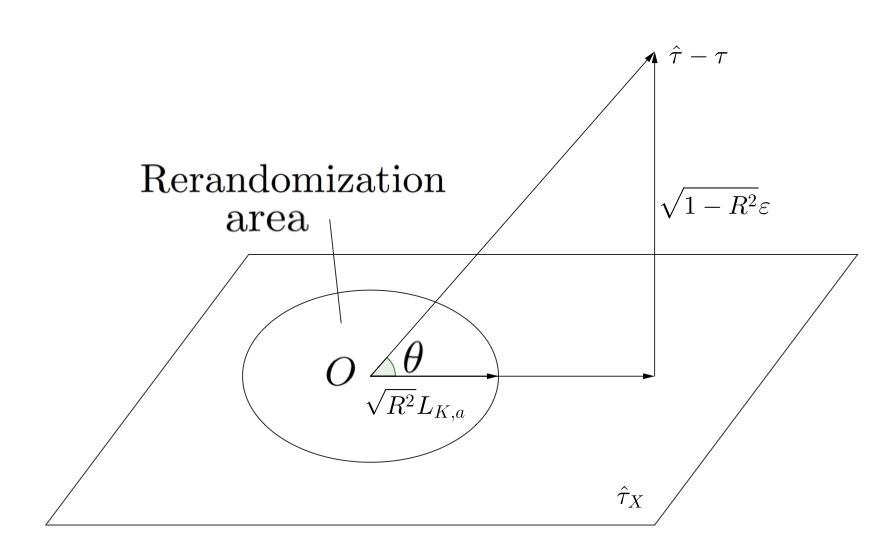
这个定理有直观的几何解释. 如图, 可以分解成一个 里的线性组合的分量, 以及一个正交 的分量, 它们的比例关系为 . ReM 只会影响第一个分量.
当 , 渐近分布退化为 CRE: . 当 接近 , , .
在 CRE 下我们有 这里 是 的有限总体的方差, 是对应的它们在 上的线性投影.
在假设 下, .
2 回归调整
如果在设计阶段我们不进行重随机化, 而是在分析阶段处理协变量的不均匀分布呢?
2.1 调整协变量的 FRT
有了协变量, FRT 的大致思路不变.
我们可以基于残差构建检验量. 我们把 在 上回归得到 .
我们可以把回归的系数作为检验量. 把 在 上回归, 得到 的系数.
伪结果策略不包含 , 因为我们要确保如果原始结果符合 , 则伪结果也符合. 而在模型结果策略中, 我们加入 的系数来看看它和 的偏离程度. 从计算上看, 策略 1 要运行 1 次, 策略 2 要运行若干次.
2.2 协方差的分析
Fisher 提出了协方差分析 (ANCOVA). 在 上对 回归, 把 的系数作为 的估计量. 记最后的结果为 .
David A. Freedman 和 Winston Lin 先后提出
- 是有偏的, 但当样本量趋于无穷时趋于
- 相比 有更大的渐近方差, 但是改为在 上 OLS 回归, 可以减小. 记为 .
Neyman 定理指出 的方差取决于潜在结果的方差, 因此我们可以试图减小潜在结果的方差. 考虑线性调整族
这里 是定义的样本均值. 当 时, 它就是 . 因为 , 所以 (固定 ) 均值为 . 我们希望找到最小化 的 .
再次引用 Neyman定理, 这里 是有限总体的方差 (分别是调节的潜在输出和个体因果效应).
基于此, 我们得到一个更保守的估计量 , 这里 是样本方差, 是实验组下 的样本均值, 和对照组下 的样本均值. 我们解如下的最优化问题: 直接应用 OLS 得到 和 . 再结合 OLS 的性质: , , 得到
从上式看出, 我们可以用单个 OLS 来获得 :
(2.1) 的 等于 在 上回归后 的系数, 也就是之前提到的 .
基于这些讨论, 我们有一个保守的估计 的量:
我们可以进一步证明上述命题中 OLS 的 EHW 标准误差几乎就是 , 这是一个 CRE 下 的保守估计. 但是这里有一个小问题: 方差 对固定的 有效, 但 用了两个估计量 , 这里额外的不确定性可能会导致有限样本下的偏差. 不过如果 , , 那么 , 这个偏差就会消失.
事实上 , 之差取决于 还是要强调, 在有限样本下回归调整可能是有害的, 必须要大的样本规模和一些潜在结果、协变量的正规性条件.
2.2.1 一个基于预测潜在结果的估计量
基于实验组的数据, 我们构建一个 的预测模型
类似地, 也有 的:
给出如下科学表:
|
|
|
|
|
|
|
|
|
? |
|
|
|
|
|
|
|
|
|
|
|
? |
|
|
|
|
? |
|
|
|
|
|
|
|
|
|
|
|
? |
|
|
|
| 则我们可以有如下估计量: |
|
|
|
|
|
| 可以证明它等于 (定义见 [[#^6a1ea6 |
这里]]). 如果我们即使对观察到的结果也进行预测, 我们有如下 投影估计量 |
|
|
|
|
| 并且它也等于 . |
|
|
|
|
|
2.2.2 从协变量不均衡性角度理解
我们可以证明等价形式 这里 , 因此我们也可以改写成 . 类似地
2.3 一些其他的注解
- ReM 和回归调整是对偶的. 具体来说, 当 很小时, ReM 下 的渐近分布几乎就是 CRE 下 的渐近分布. 所以 ReM 在设计阶段使用协变量, 而回归调整中在分析阶段协变量.
- 回归调整和后分层等价. 如果我们有离散的协变量 且有 类, 我们可以创造 个中心化的 (0 均值) 的虚拟变量 这里 是
的比例. 此时, 回归调整和 SRE 等价:
基于 的 在数值上等于基于 后分层的 .
- 一个常见的协变量是在进行试验前的结果. 此时我们可以使用 difference-in-difference (双重差分法) 这是无偏估计, 有一个保守的方差 这里 是增益值 的样本均值.
2.4 到 SRE 的推广
回顾 SRE. 如果每个分层都很大, 可以在分层上进行回归调整 对应的保守方差估计